ETL is the process by which data is extracted from data sources (that are not optimized for analytics), and moved to a central host (which is). The exact steps in that process might differ from one ETL tool to the next, but the end result is the same.
At its most basic, the ETL process encompasses data extraction, transformation, and loading. While the abbreviation implies a neat, three-step process – extract, transform, load – this simple definition doesn’t capture:
- The transportation of data
- The overlap between each of these stages
- How new technologies are changing this flow
Traditional ETL process
Historically, the ETL process has looked like this:
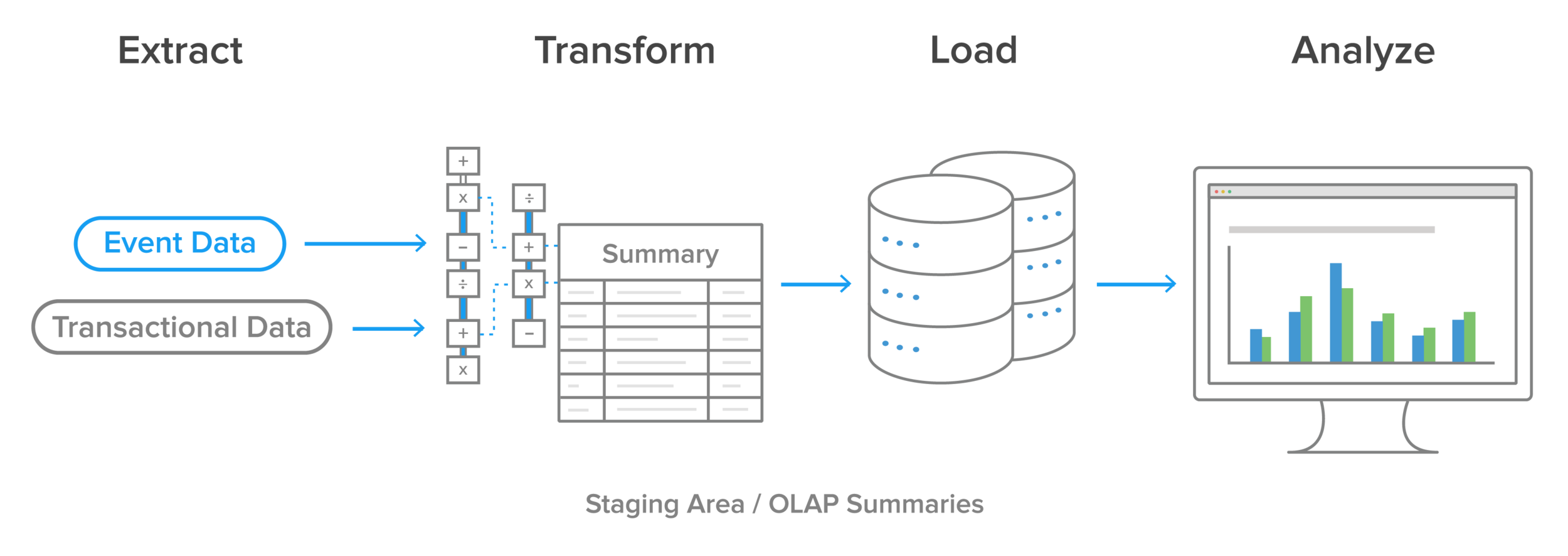
Data is extracted from online transaction processing (OLTP) databases, today more commonly known just as ‘transactional databases’, and other data sources. OLTP applications have high throughput, with large numbers of read and write requests. They do not lend themselves well to data analysis or business intelligence tasks. Data is then transformed in a staging area. These transformations cover both data cleansing and optimizing the data for analysis. The transformed data is then loaded into an online analytical processing (OLAP) database, today more commonly known as just an analytics database. For more info ETL Testing Training
Business intelligence (BI) teams then run queries on that data, which are eventually presented to end users, or to individuals responsible for making business decisions, or used as input for machine learning algorithms or other data science projects. One common problem encountered here is if the OLAP summaries can’t support the type of analysis the BI team wants to do, then the whole process needs to run again, this time with different transformations.
Data Warehouse ETL process
Modern technology has changed most organizations’ approach to ETL, for several reasons.
The biggest is the advent of powerful analytics warehouses like Amazon Redshift and Google BigQuery. These newer cloud-based analytics databases have the horsepower to perform transformations in place rather than requiring a special staging area.
Another is the rapid shift to cloud-based SaaS applications that now house significant amounts of business-critical data in their own databases, accessible through different technologies such as APIs and webhooks.
Also, data today is frequently analyzed in raw form rather than from preloaded OLAP summaries. This has led to the development of lightweight, flexible, and transparent ETL systems with processes that look something like this: More ETL Testing Certification
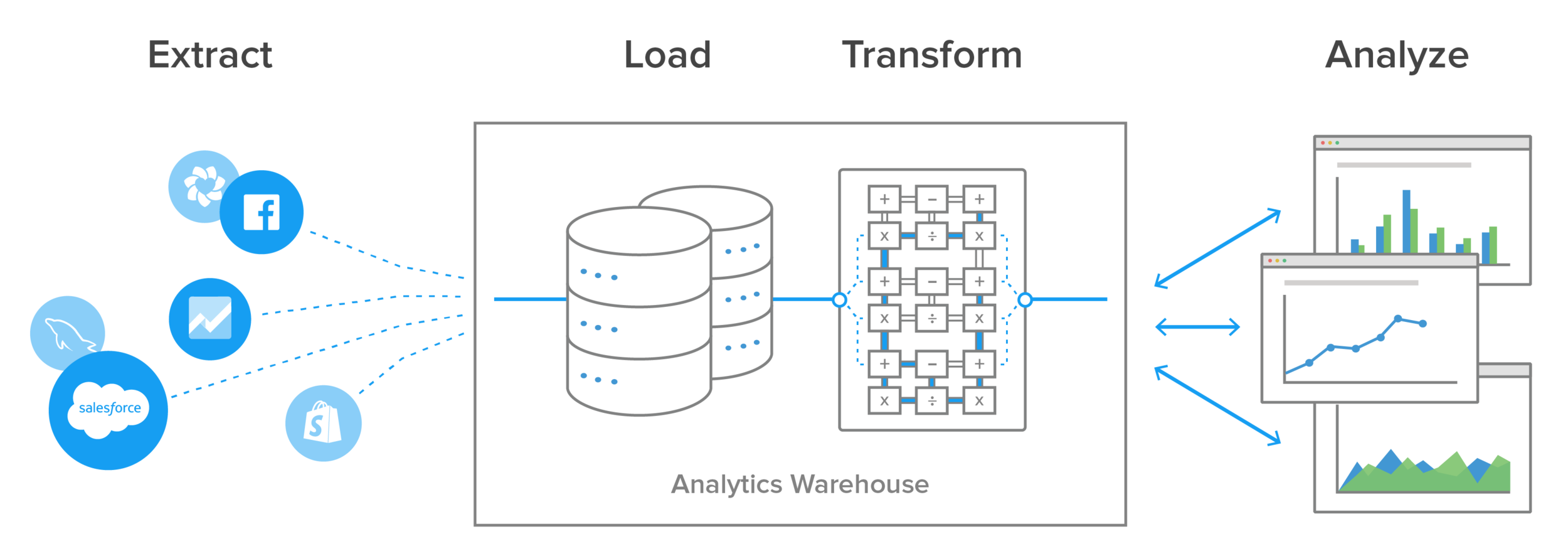
A comtemporary ETL process using a Data Warehouse
The biggest advantage to this setup is that transformations and data modeling happen in the analytics database, in SQL. This gives the BI team, data scientists, and analysts greater control over how they work with it, in a common language they all understand.
Critical ETL components
Regardless of the exact ETL process you choose, there are some critical components you’ll want to consider:
- Support for change data capture (CDC) (a.k.a. binlog replication): Incremental loading allows you to update your analytics warehouse with new data without doing a full reload of the entire data set. We say more about this in the ETL Load section.
- Auditing and logging: You need detailed logging within the ETL pipeline to ensure that data can be audited after it’s loaded and that errors can be debugged.
- Handling of multiple source formats: To pull in data from diverse sources such as Salesforce’s API, your back-end financials application, and databases such as MySQL and MongoDB, your process needs to be able to handle a variety of data formats.
- Fault tolerance: In any system, problems inevitably occur. ETL systems need to be able to recover gracefully, making sure that data can make it from one end of the pipeline to the other even when the first run encounters problems.
- Notification support: If you want your organization to trust its analyses, you have to build in notification systems to alert you when data isn’t accurate. These might include:
- Proactive notification directly to end users when API credentials expire
- Passing along an error from a third-party API with a description that can help developers debug and fix an issue
- If there’s an unexpected error in a connector, automatically creating a ticket to have an engineer look into it
- Utilizing systems-level monitoring for things like errors in networking or databases
- Low latency: Some decisions need to be made in real time, so data freshness is critical. While there will be latency constraints imposed by particular source data integrations, data should flow through your ETL process with as little latency as possible.
- Scalability: As your company grows, so will your data volume. All components of an ETL process should scale to support arbitrarily large throughput.
- Accuracy: Data cannot be dropped or changed in a way that corrupts its meaning. Every data point should be auditable at every stage in your process.
To get in-depth knowledge enroll for a live free demo on ETL Testing online training
