Be yourself; Everyone else is already taken.
— Oscar Wilde.
This is the first post on my new blog. I’m just getting this new blog going, so stay tuned for more. Subscribe below to get notified when I post new updates.
Be yourself; Everyone else is already taken.
— Oscar Wilde.
This is the first post on my new blog. I’m just getting this new blog going, so stay tuned for more. Subscribe below to get notified when I post new updates.

Any enterprise organization looking for a human capital management (HCM) solution should compare Workday vs. SAP SuccessFactors. These vendors are titans of the cloud-based HCM space. And given the mission-critical tasks you’ll need such a system to perform, you shouldn’t skimp when it comes to researching an HCM purchase. We provide this in-depth comparison to help you make a more informed decision about whether or not Workday or SuccessFactors is right for you, but there’s an easier way.
If you’d rather speed up your research process without forgoing quality of research, we’re here to help. Use our Product Selection Tool to receive five personalized HCM software recommendations, delivered straight to your inbox. It’s free to use our tool, and it takes less than five minutes to get your vendor shortlist. Get started by clicking the banner below. For more info Workday training
What is Workday?
Workday is a cloud-based ERP software provider that describes itself as a “…single system for finance, HR, and planning.” A software-as-a-service (SaaS) pioneer, Workday was built by the same brains behind what is now Oracle PeopleSoft. It works best for medium and large enterprises. Workday offers many different products, but for the sake of this article, we’ll focus exclusively on its HCM solution, which performs functions like human resource management (HRM), reporting and analytics, talent management, compliance, payroll management, and learning and development. Workday is a publicly-traded company and is trusted by major brands such as National Geographic, Netflix, and AirBnB.Get Pricing
From the massive ERP software company SAP comes SuccessFactors, a cloud-based HCM solution for organizations of all sizes. SuccessFactors is one of Workday’s top competitors, and it works well for companies with a global presence. Inside the system, you’ll find many of the same features offered by similar products in the HCM space: a human resources information system (HRIS), time and attendance, recruiting and onboarding, learning and development, and workforce planning and analytics. Organizations from around the world trust SuccessFactors as their HCM, from the San Francisco 49ers in the United States to Jaguar Land Rover in the United Kingdom.Get Pricing
At the heart of any HCM system is an HRIS that performs basic functions like managing benefits, time-off, compensation, and org charts. Both Workday and SuccessFactors include an HRIS, but they function a little bit differently for each vendor.
Workday presents users with a dashboard view when they access the system’s HRIS tool. Here, you can see quick stats such as new hire turnover rate, headcount by country, and employer cost by country. Workday’s HRIS includes task management tools for HR professionals, workflow management, and simple org charts for visualizing the company’s hierarchical structure.
For employees, there’s a self-service portal for submitting time-off requests, logging sick days, and updating contact and banking information, among other functions. Overall, this HRIS is intuitive and easy to use while still giving HR pros access to powerful insights about better managing talent. Learn more skills from Workday integration training
SAP SuccessFactors also features an employee self-service portal for submitting time-off requests and updating personal information. This portal can be accessed through SuccessFactors’ web-based app or through its mobile apps for iOS and Android.
HR pros using SuccessFactors can view and edit company org charts, ensure legal compliance with automatically updated local and global regulations, administer benefits around the world, and customize dashboard views to get a quick overview of your company’s operations. The system also allows for task management, compensation management, and rewards and recognition.
Accessing the payroll feature in Workday takes you to a dashboard overview of all your payroll processes. Here you can view stats like headcount by pay group, payroll taxes by month, and more. Workday bills itself as a global solution, and while you can process international payroll, it’s currently limited to four countries at the time of publishing: the United States, Canada, the United Kingdom, and France. If you need to run payroll in any other countries, you can integrate Workday with your third-party payroll provider to generate payroll reports in Workday.
If you need to run payroll in more countries than those Workday supports, SuccessFactors might be a better fit for you. SuccessFactors lets you run payroll in over 40 countries, and it stays up-to-date on local payroll processes and regulations. You can view payroll analysis in real time with reports like total employer taxes, total net and gross comparisons of payroll by period, and total employee taxes. Alerting is another useful feature that notifies you of payroll issues or anomalies.
Workday helps to keep you compliant around the world by letting you set location, date, time, and privacy preferences unique to each location where you do business. The software encrypts your data and automatically translates apps and data into 35 languages, and you can control the level of visibility other employees have into the system based on their geographic location. For regulatory updates, Workday offers a global library of regulations for you to review, and the system automatically notifies you of new legislation that might affect your business.
SAP SuccessFactors also supports global compliance through time zones, date formats, currencies, and custom fields by geographic location. The system lets you collect all the necessary employment information from new hires depending on local regulations and local best business practices, and the software even displays information differently based on local customs to make employees feel at home. For translation of apps and data, SuccessFactors works with over 40 languages and various dialects. For new regulations, SuccessFactors keeps track of legal changes and notifies you accordingly.
To get in-depth knowledge, enroll for a live free demo on Workday Online Training
As they face ever-changing business requirements, our customers need to adapt quickly and effectively. When we designed Workday’s original architecture, we considered agility a fundamental requirement. We had to ensure the architecture was flexible enough to accommodate technology changes, the growth of our customer base, and regulatory changes, all without disrupting our users. We started with a small number of services. The abstraction layers we built into the original design gave us the freedom to refactor individual services and adopt new technologies. These same abstractions helped us transition to the many loosely-coupled distributed services we have today.
At one point in Workday’s history, there were just four services: User Interface (UI), Integration, OMS, and Persistence. Although the Workday architecture today is much more complex, we still use the original diagram below to provide a high-level overview of our services.
At the heart of the architecture are the Object Management Services (OMS), a cluster of services that act as an in-memory database and host the business logic for all Workday applications. The OMS cluster is implemented in Java and runs as a servlet within Apache Tomcat. The OMS also provides the runtime for XpressO — Workday’s application programming language in which most of our business logic is implemented. Reporting and analytics capabilities in Workday are provided by the Analytics service which works closely with the OMS, giving it direct access to Workday’s business objects.
The Persistence Services include a SQL database for business objects and a NoSQL database for documents. The OMS loads all business objects into memory as it starts up. Once the OMS is up and running, it doesn’t rely on the SQL database for read operations. The OMS does, of course, update the database as business objects are modified. Using just a few tables, the OMS treats the SQL database as a key-value store rather than a relational database. Although the SQL database plays a limited role at runtime, it performs an essential role in the backup and recovery of data.
The UI Services support a wide variety of mobile and browser-based clients. Workday’s UI is rendered using HTML and a library of JavaScript widgets. The UI Services are implemented in Java and Spring. Get more info from Workday Online Training
The Integration Services provide a way to synchronize the data stored within Workday with the many different systems used by our customers. These services run integrations developed by our partners and customers in a secure, isolated, and supervised environment. Many pre-built connectors are provided alongside a variety of data transformation technologies and transports for building custom integrations. The most popular technologies for custom integrations are XSLT for data transformation and SFTP for data delivery.
The Deployment tools support new customers as they migrate from their legacy systems into Workday. These tools are also used when existing customers adopt additional Workday products.
Workday’s Operations teams monitor the health and performance of these services using a variety of tools. Realtime health information is collected by Prometheus and Sensu and displayed on Wavefront dashboards as time series graphs. Event logs are collected using a Kafka message bus and stored on the Hadoop Distributed File System, commonly referred to as HDFS. Long-term performance trends can be analyzed using the data in HDFS.
As we’ve grown, Workday has scaled out its services to support larger customers, and to add new features. The original few services have evolved into multiple discrete services, each one focused on a specific task. You can get a deeper understanding of Workday’s architecture by viewing a diagram that includes these additional services. Click play on the video above to see the high-level architecture diagram gain detail as it transforms into a diagram that resembles the map of a city. (The videos in this post contain no audio.)
This more detailed architecture diagram shows multiple services grouped together into districts:
These services are connected by a variety of different pathways. A depiction of these connections resembles a city map rather than a traditional software architecture diagram. As with any other city, there are districts with distinct characteristics. We can trace the roots of each district back to the services in our original high-level architecture diagram.
There are a number of landmark services that long-time inhabitants of Workday are familiar with. Staying with the city metaphor, users approaching through Workday Way arrive at the UI services before having their requests handled by the Transaction Services. Programmatic access to the Transaction Service is provided by the API Gateway. The familiar Business Data Store is clearly visible, alongside a relatively new landmark: the Big Data Store where customers can upload large volumes of data for analysis. The Big Data Store is based on HDFS. Workday’s Operations team monitors the health and performance of the city using the monitoring Console based on Wavefront.
Zooming in on the User Interface district allows us to see the many services that support Workday’s UI.
The original UI service that handles all user generated requests is still in place. Alongside it, the Presentation Services provide a way for customers and partners to extend Workday’s UI. Workday Learning was our first service to make extensive use of video content. These large media files are hosted on a content delivery network that provides efficient access for our users around the globe. Worksheets and Workday Prism Analytics also introduced new ways of interacting with the Workday UI. Clients using these features interact with those services directly. These UI services collaborate through the Shared Session service which is based on Redis. This provides a seamless experience as users move between services. Learn more from Workday Integration Training
This architecture also illustrates the value of using metadata-driven development to build enterprise applications.
Application developers design and implement Workday’s applications using XpressO, which runs in the Transaction Service. The Transaction Service responds to requests by providing both data and metadata. The UI Services use the metadata to select the appropriate layout for the client device. JavaScript-based widgets are used to display certain types of data and provide a rich user experience. This separation of concerns isolates XpressO developers from UI considerations. It also means that our JavaScript and UI service developers can focus on building the front-end components. This approach has enabled Workday to radically change its UI over the years while delivering a consistent user experience across all our applications without having to rewrite application logic.
The Object Management Services started life as a single service which we now refer to as the Transaction Service. Over the years the OMS has expanded to become a collection of services that manage a customer’s data. A brief history lesson outlining why we introduced each service will help you to understand their purpose. Click play on the video below to see each service added to the architecture.https://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2FBa99eBydrrw%3Ffeature%3Doembed&url=http%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3DBa99eBydrrw&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2FBa99eBydrrw%2Fhqdefault.jpg&key=a19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=youtube
Originally, there was just the Transaction Service and a SQL database in which both business data and documents were stored. As the volume of documents increased, we introduced a dedicated Document Store based on NoSQL.
Larger customers brought many more users and the load on the Transaction Service increased. We introduced Reporting Services to handle read-only transactions as a way of spreading the load. These services also act as in-memory databases and load all data on startup. We introduced a Cache to support efficient access to the data for both the Transaction Service and Reporting Services. Further efficiencies were achieved by moving indexing and search functionality out of the Transaction Service and into the Cache. The Reporting Services were then enhanced to support additional tasks such as payroll calculations and tasks run on the job framework.
Search is an important aspect of user interaction with Workday. The global search box is the most prominent search feature and provides access to indexes across all customer data. Prompts also provide search capabilities to support data entry. Some prompts provide quick access across hundreds of thousands of values. Use cases such as recruiting present new challenges as a search may match a large number of candidates. In this scenario, sorting the results by relevance is just as important as finding the results.
A new search service based on Elasticsearch was introduced to scale out the service and address these new use cases. This new service replaces the Apache Lucene based search engine that was co-located with the Cache. A machine learning algorithm that we call the Query Intent Analyzer builds models based on an individual customer’s data to improve both the matching and ordering of results by relevance.
Scaling out the Object Management Services is an ongoing task as we take on more and larger customers. For example, more of the Transaction Service load is being distributed across other services. Update tasks are now supported by the Reporting Services, with the Transaction Service coordinating activity. We are currently building out a fabric based on Apache Ignite which will sit alongside the Cache. During 2018 we will move the index functionality from the Cache onto the Fabric. Eventually, the Cache will be replaced by equivalent functionality running on the Fabric.
Integrations are managed by Workday and deeply embedded into our architecture. Integrations access the Transaction Service and Reporting Services through the API Gateway.
An integration may be launched based on a schedule, manually by a user, or as a side effect of an action performed by a user. The Integration Supervisor, which is implemented in Scala and Akka, manages the grid of compute resources used to run integrations. It identifies a free resource and deploys the integration code to it. The integration extracts data through the API Gateway, either by invoking a report as a service or using our SOAP or REST APIs. A typical integration will transform the data to a file in Comma Separated Values (CSV) or Extensible Markup Language (XML) and deliver it using Secure File Transfer Protocol (SFTP). The Integration Supervisor will store a copy of the file and audit files in the Documents Store before freeing up the compute resources for the next integration.
There are three main persistence solutions used within Workday. Each solution provides features specific to the kind of data it stores and the way that data is processed.
To get in-depth knowledge, enroll for a live free demo on Workday training
Workday is a cloud financial management and human capital management software that seamlessly combines finance and HR for greater business performance and visibility into organizational data.
Use the Workday REST integration connector to sync data between your Workday REST instance and other cloud applications.
The Workday REST connector works best when you are executing workflow-centric actions (e.g. approve inbox task). If your use case requires you to work with larger datasets (e.g. full reports from Workday) or with custom reports/objects, use the Workday integration connector instead
The Workday REST connector uses the Workday REST API. Workday recommends using an Integration System User (ISU) for integration using third party services like Workato.
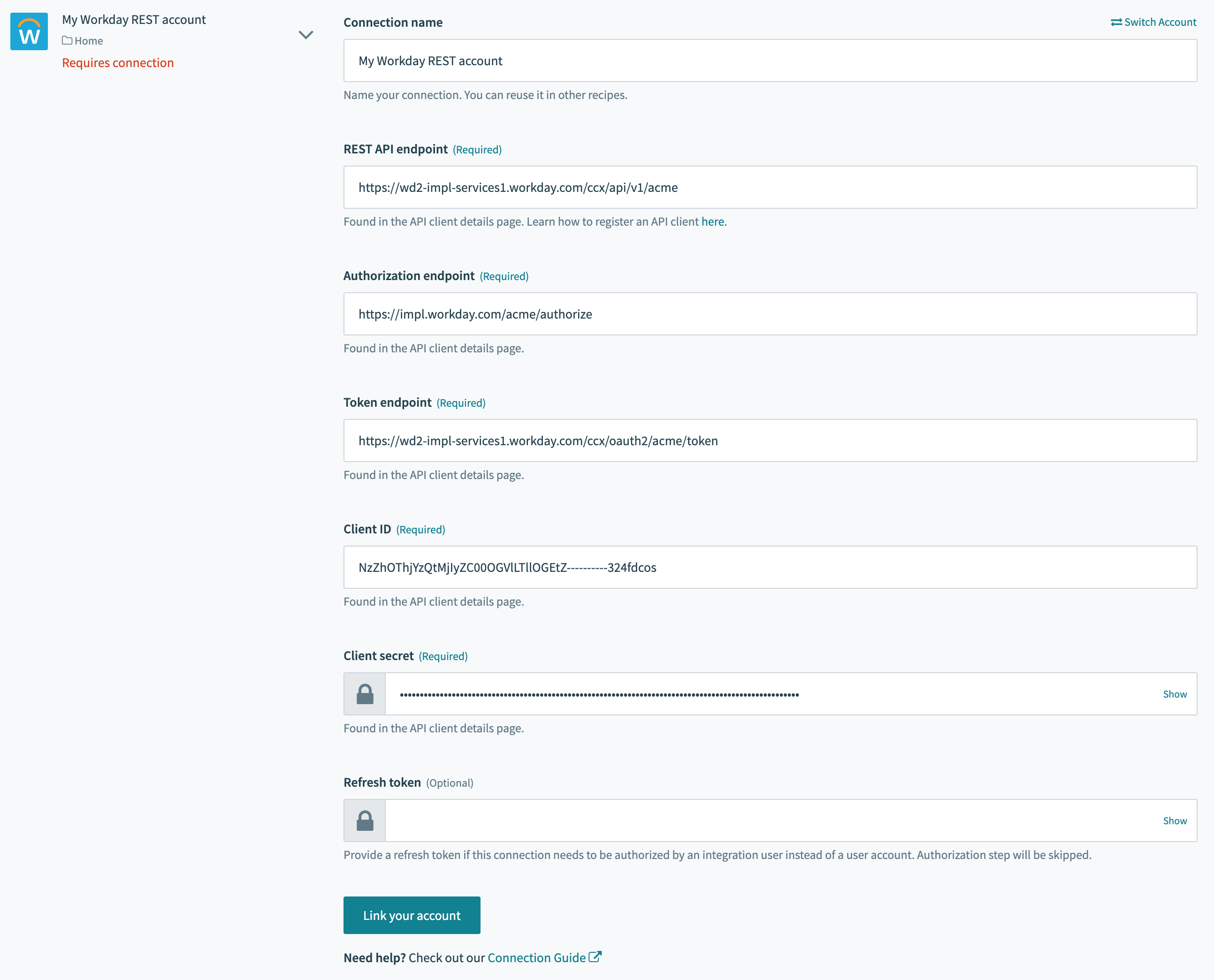 Workday connection fields
Workday connection fields
You will need to create an API client to connect to Workday REST API. There are 2 ways to connect using API clients:
Use a regular API Client to authorize a connection to the REST API using a user account.
First, navigate to the View API Clients page by typing it into the search bar. You should see this screen. Here, you will see the endpoints required for the connection. Take note of REST API endpoint, Token endpoint and Authorization endpoint.
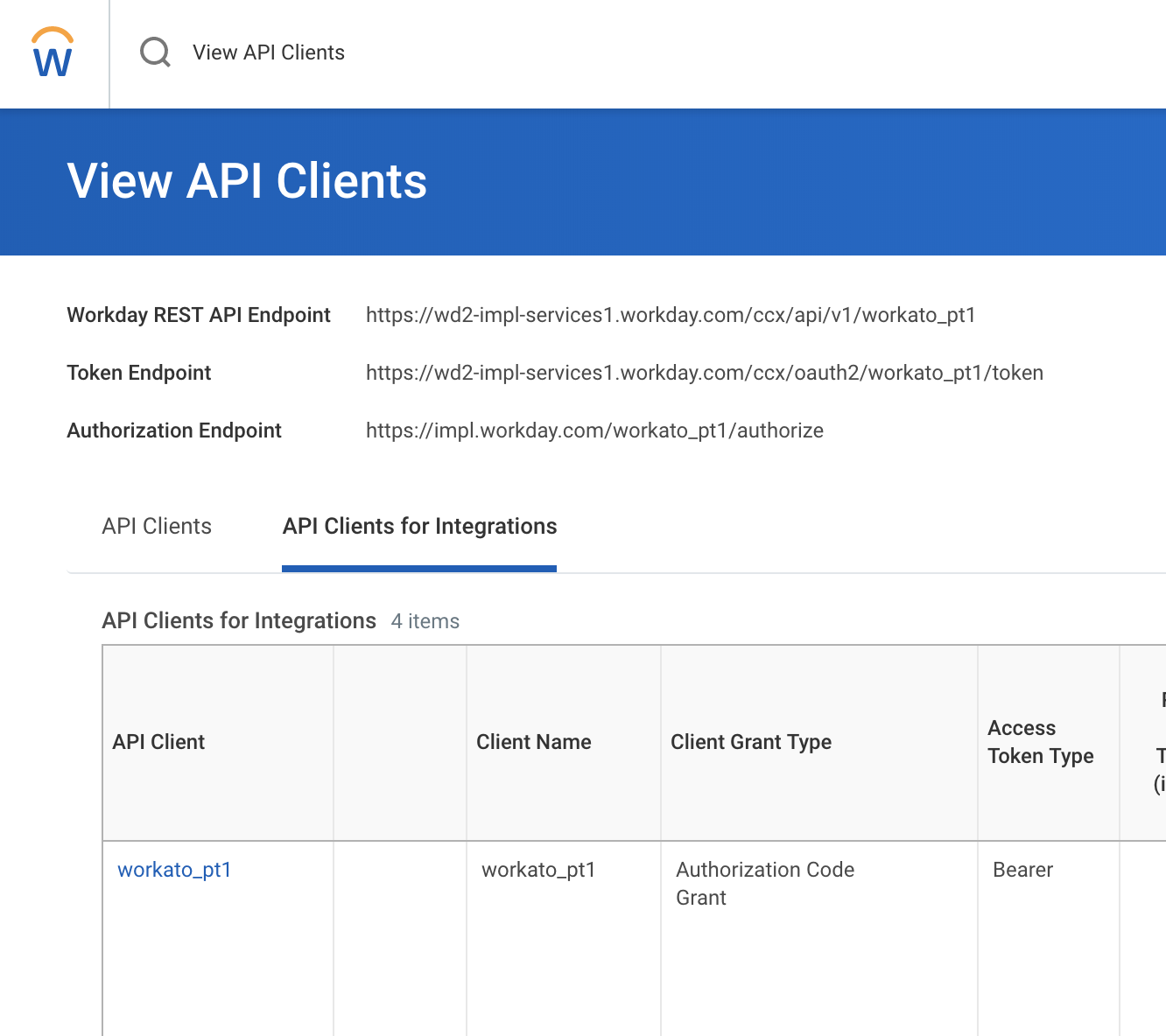 View API clients
View API clients
Click on an existing API Clients that is available to integration if there are any. Otherwise, you need to create a new one. Navigate to Register API Client in your Workday instance.
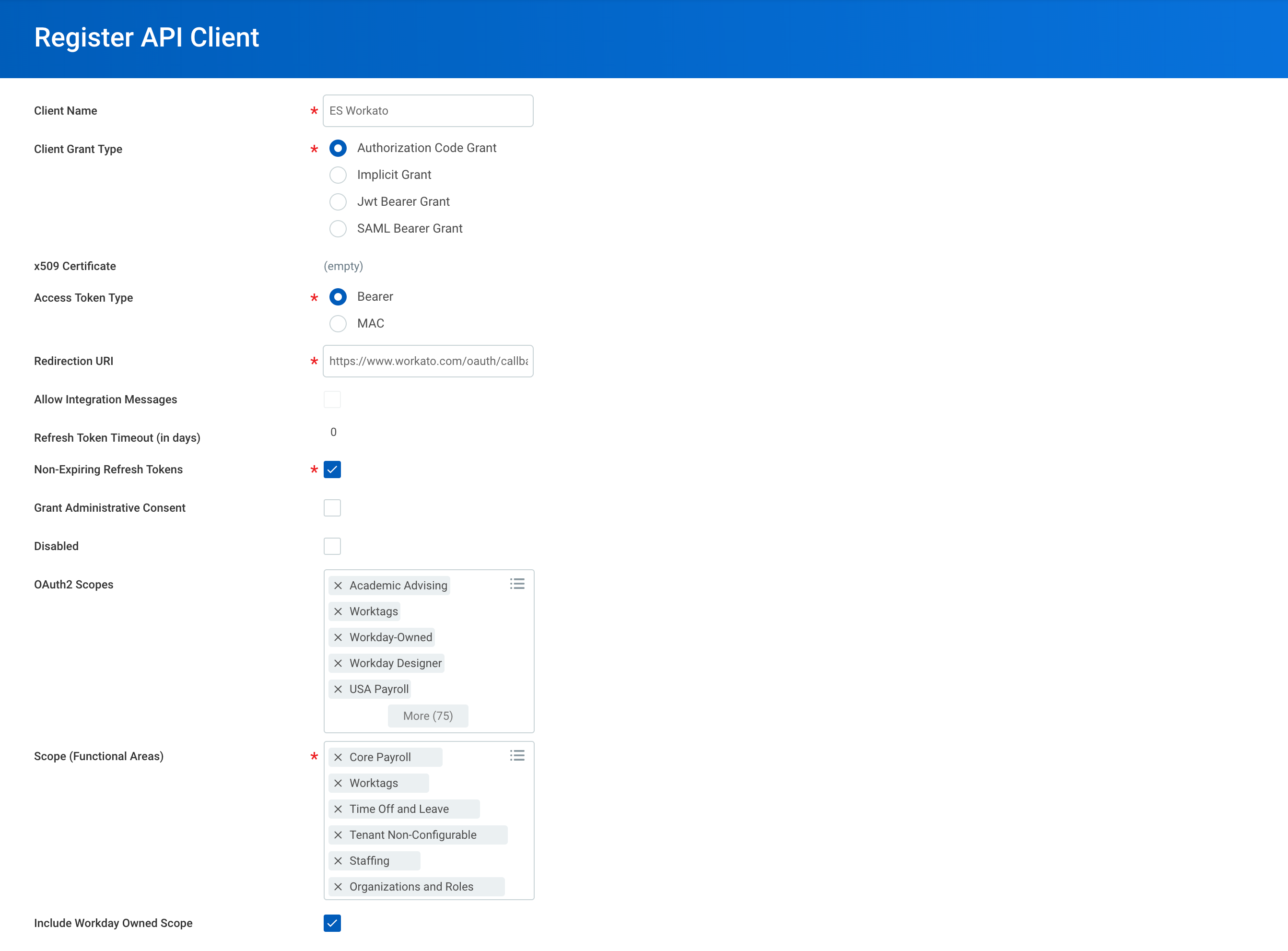 Registering a new client
Registering a new client
https://www.workato.com/oauth/callback as the Redirection URL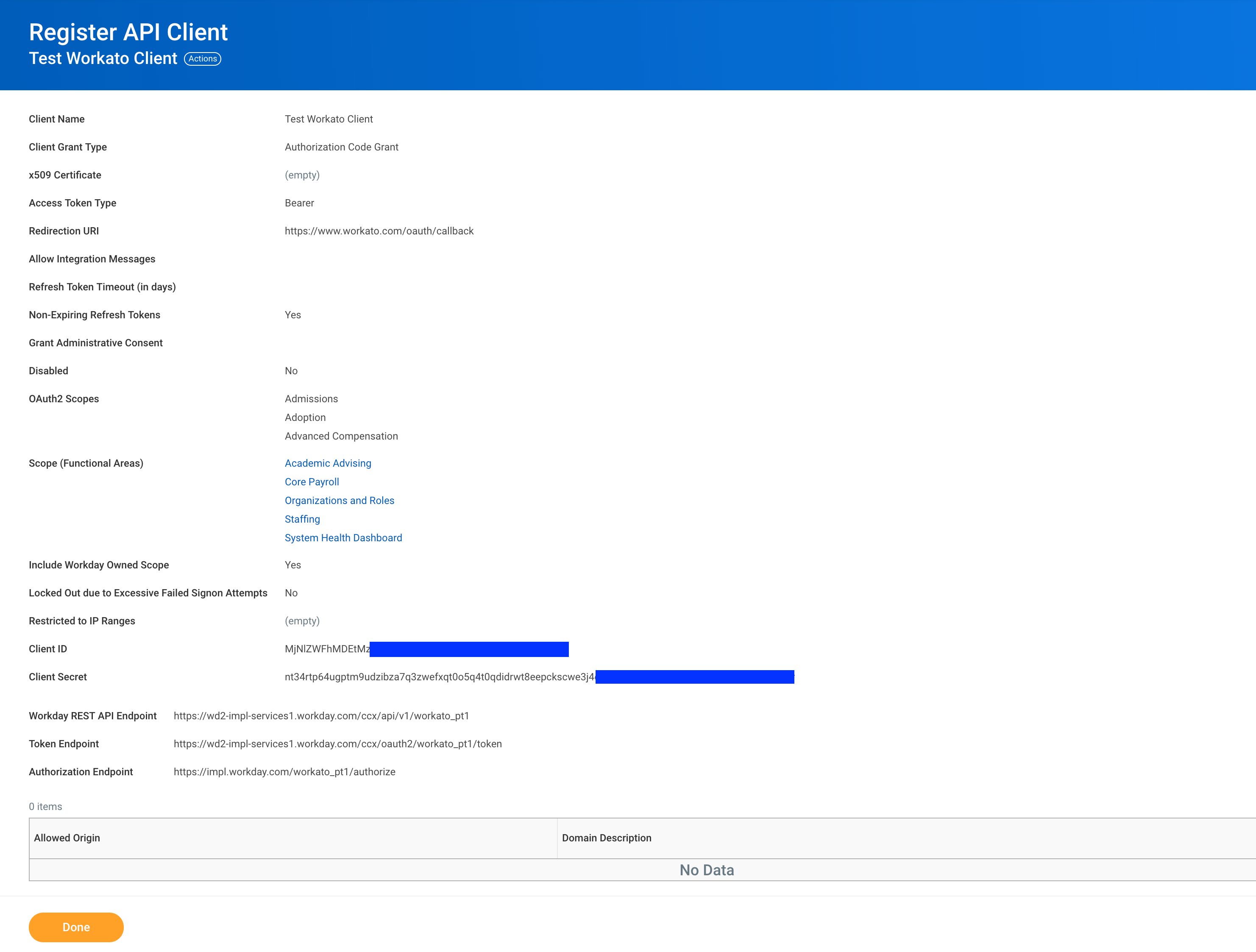 API client details
API client details
Remember to save the Client ID and Client Secret before clicking Done. This will be required to create a Workday REST connection.
If you wish to use a manually generated token to connect to Workday, you will need to register an API client for integration. This is required when using an ISU that does not have login access and is used only for API access.
Navigate to Register API Client for integration in your Workday instance.
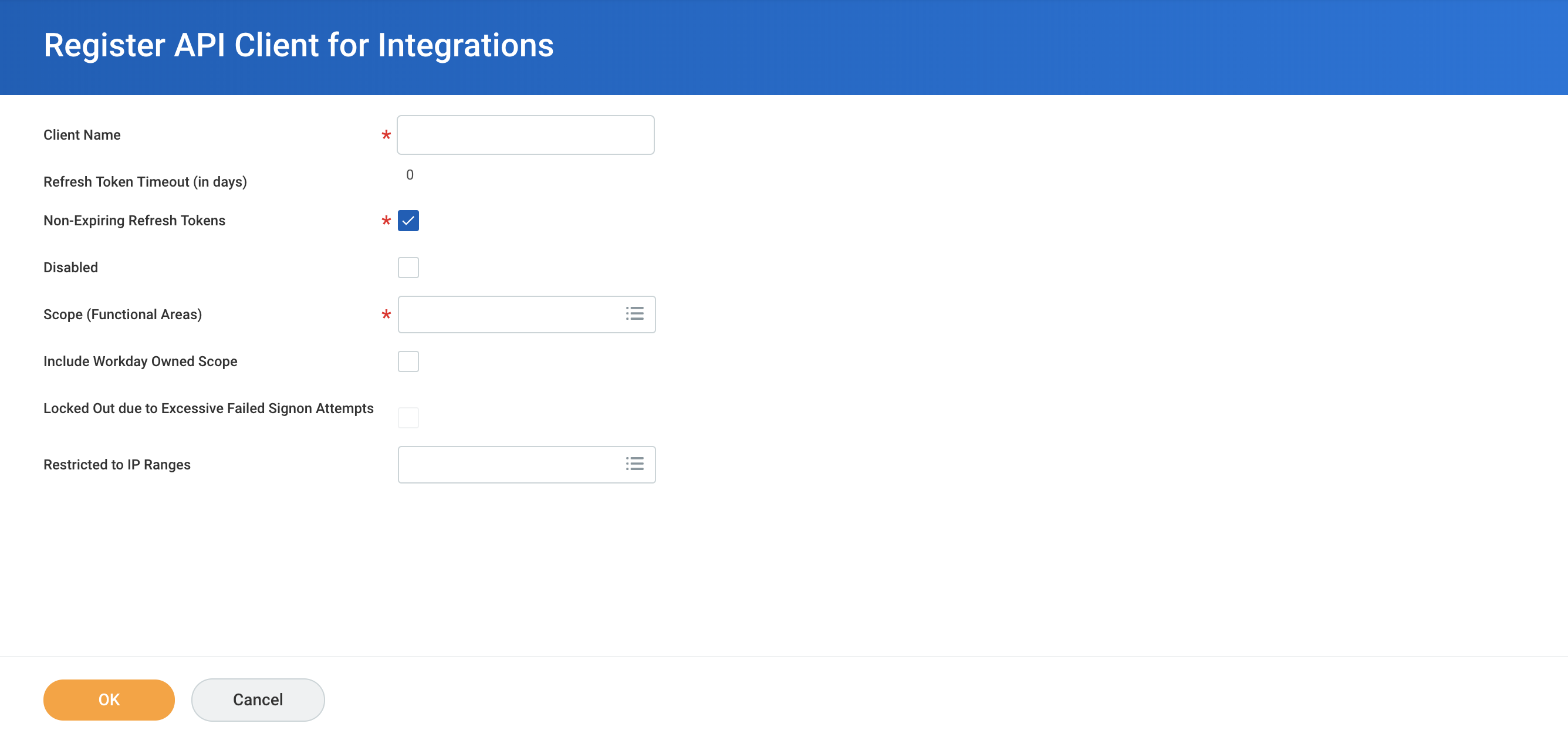 Registering a new client for Integrations
Registering a new client for Integrations
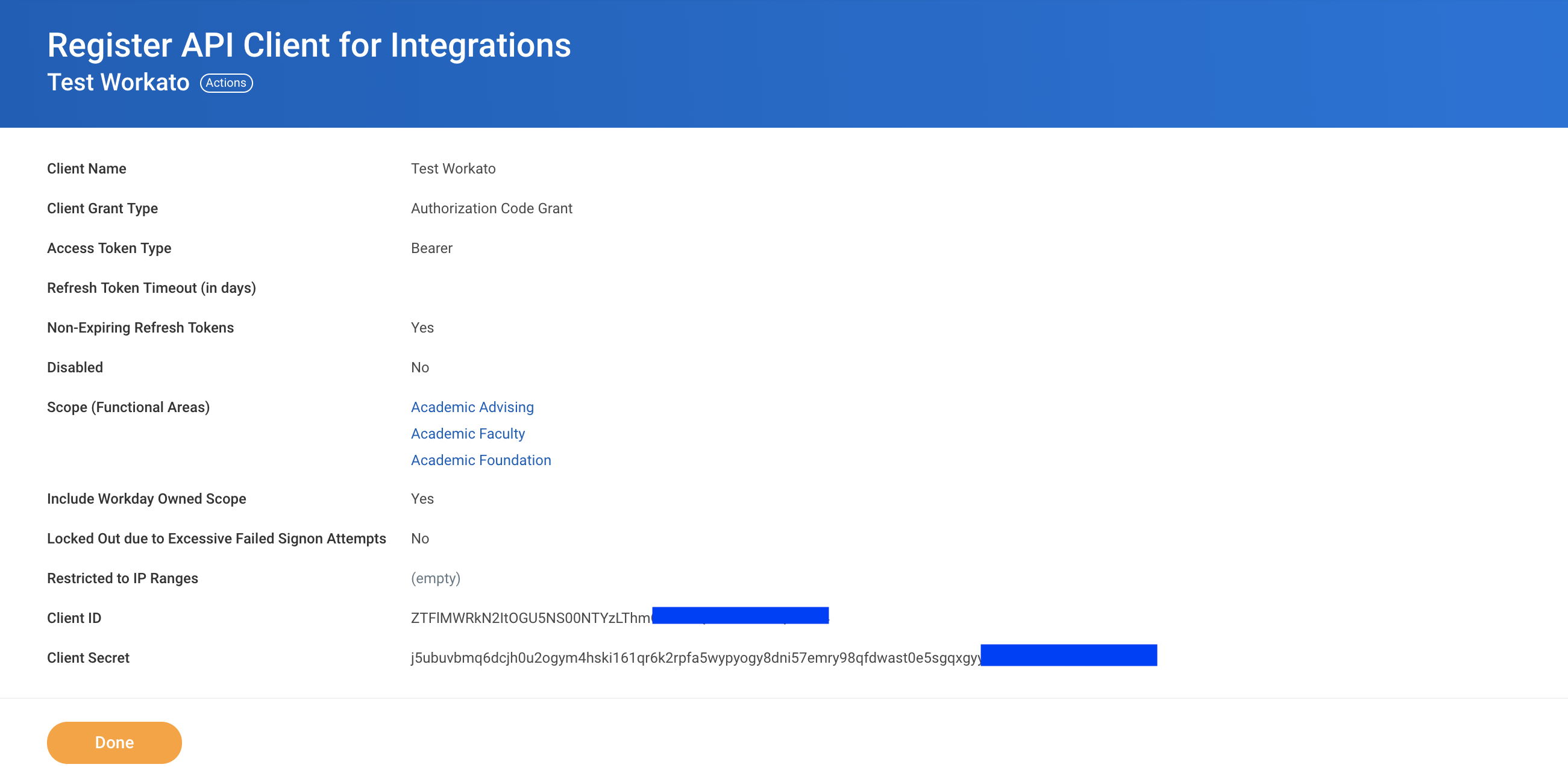 API client details
API client details
Remember to save the Client ID and Client Secret before clicking Done. This will be required to create a Workday REST connection.
Lastly, navigate to Action > API Client > Manage Refresh Tokens for Integrations.
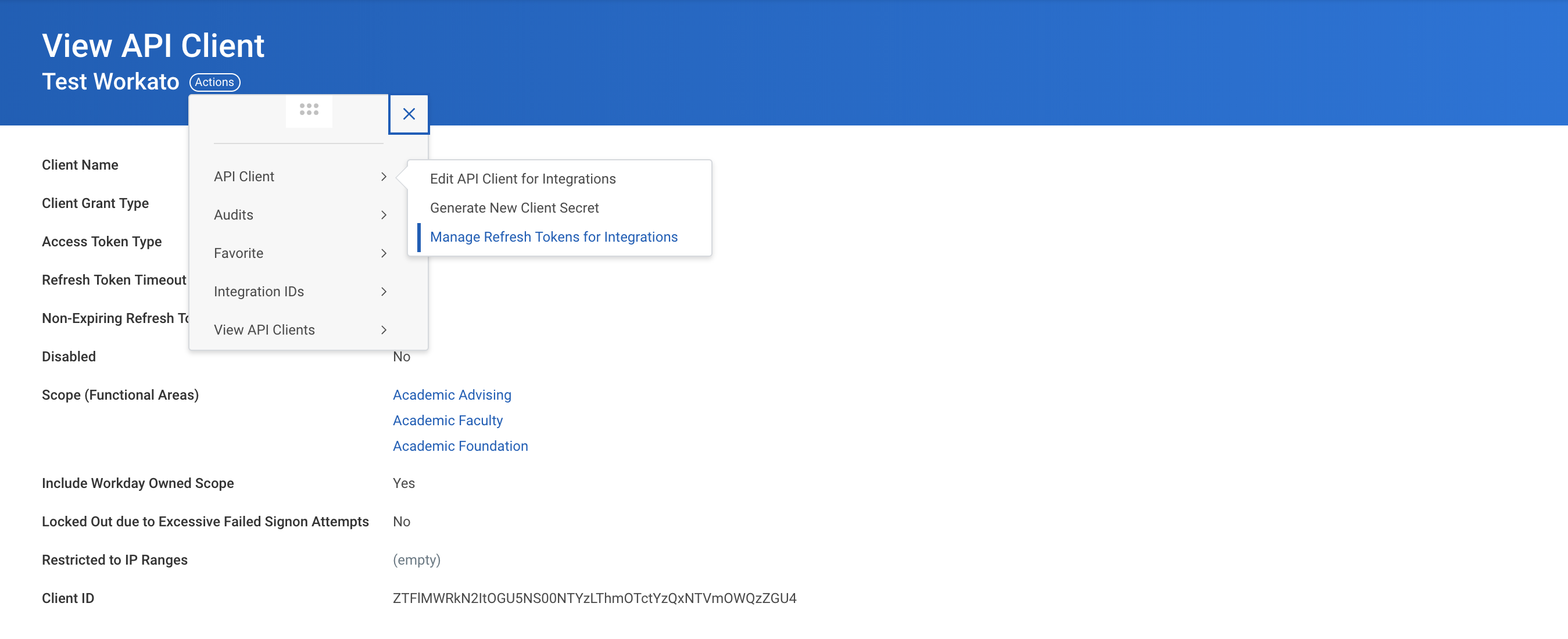 Generate refresh token
Generate refresh token
Select the Integration user to perform all recipe actions.
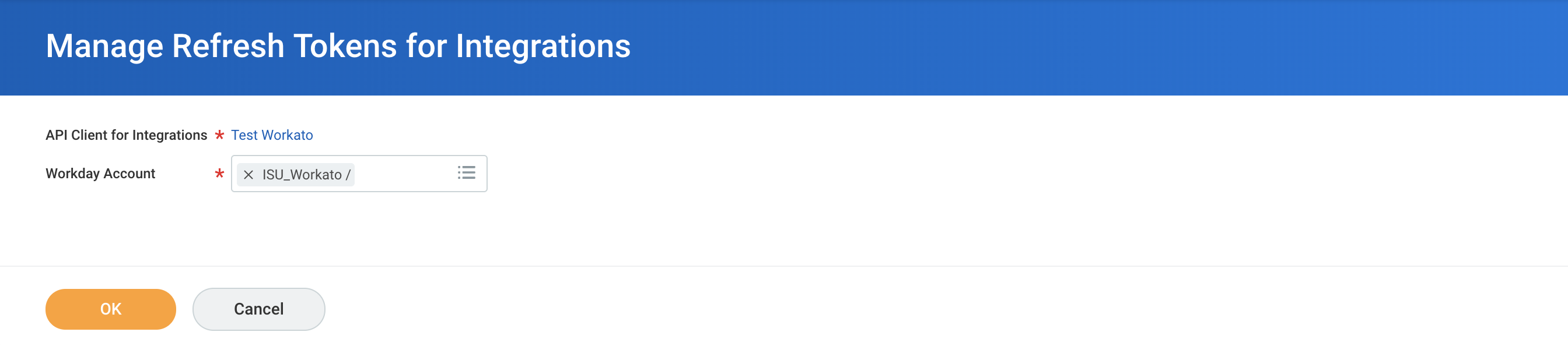 Select refresh token for ISU
Select refresh token for ISU
If there are no existing refresh tokens, select Generate new refresh token and copy the new Refresh token. This will be required to create a Workday REST connection.
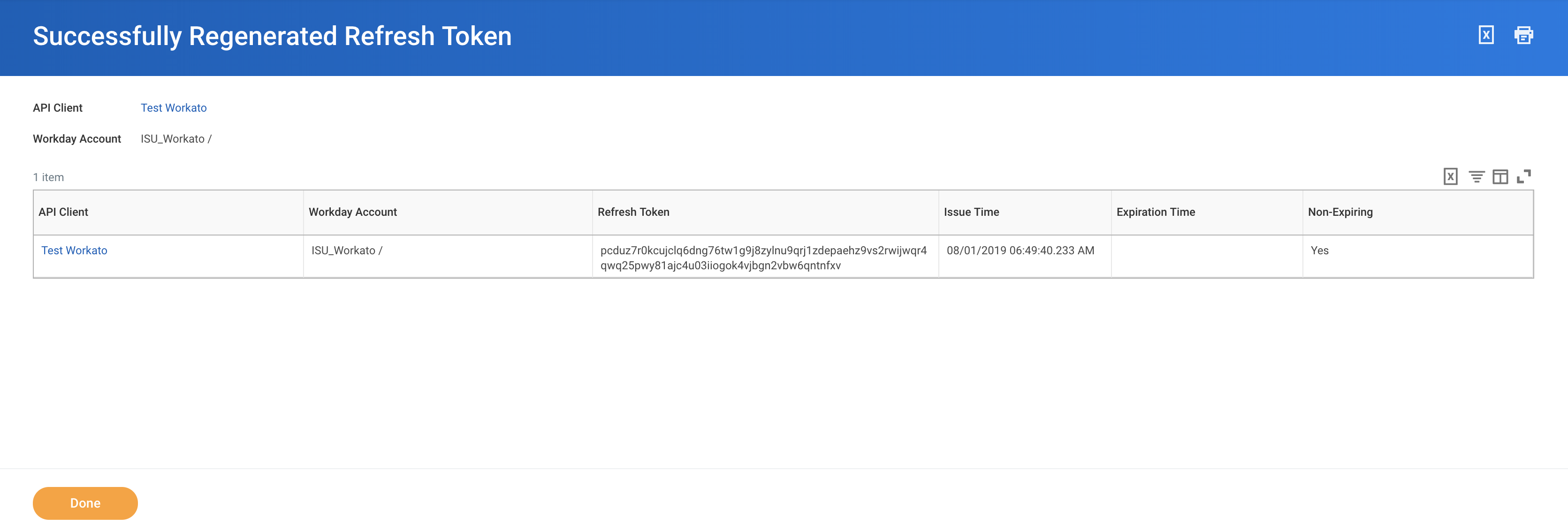 Refresh token for ISU
Refresh token for ISU
To get in-depth knowledge, enroll for a live free demo on Workday Online Training

In this post, I am going to discuss Apache Spark and how you can create simple but robust ETL pipelines in it. You will learn how Spark provides APIs to transform different data format into Data frames and SQL for analysis purpose and how one data source could be transformed into another without any hassle.
Apache Spark is an open-source distributed general-purpose cluster-computing framework. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
In short, Apache Spark is a framework which is used for processing, querying and analyzing Big data. Since the computation is done in memory hence it’s multiple fold fasters than the competitors like MapReduce and others. The rate at which terabytes of data is being produced every day, there was a need for a solution that could provide real-time analysis at high speed. Some of the Spark features are:
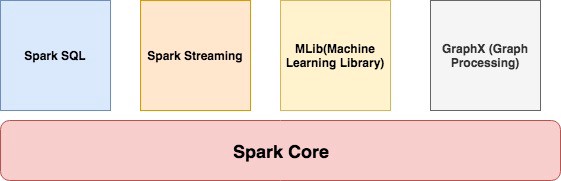
It contains the basic functionality of Spark like task scheduling, memory management, interaction with storage, etc. Get more from ETL Testing Training
It is a set of libraries used to interact with structured data. It used an SQL like interface to interact with data of various formats like CSV, JSON, Parquet, etc.
Spark Streaming is a Spark component that enables the processing of live streams of data. Live streams like Stock data, Weather data, Logs, and various others.
MLib is a set of Machine Learning Algorithms offered by Spark for both supervised and unsupervised learning
It is Apache Spark’s API for graphs and graph-parallel computation. It extends the Spark RDD API, allowing us to create a directed graph with arbitrary properties attached to each vertex and edge. It provides a uniform tool for ETL, exploratory analysis and iterative graph computations.
Spark supports the following resource/cluster managers:
Download the binary of Apache Spark from here. You must have Scala installed on the system and its path should also be set.
For this tutorial, we are using version 2.4.3 which was released in May 2019. Move the folder in /usr/local
mv spark-2.4.3-bin-hadoop2.7 /usr/local/spark
And then export the path of both Scala and Spark.
#Scala Path
export PATH="/usr/local/scala/bin:$PATH"#Apache Spark path
export PATH="/usr/local/spark/bin:$PATH"
Invoke the Spark Shell by running the spark-shell command on your terminal. If all goes well, you will see something like below:

It loads the Scala based shell. Since we are going to use Python language then we have to install PySpark.
pip install pyspark
Once it is installed you can invoke it by running the command pyspark in your terminal:
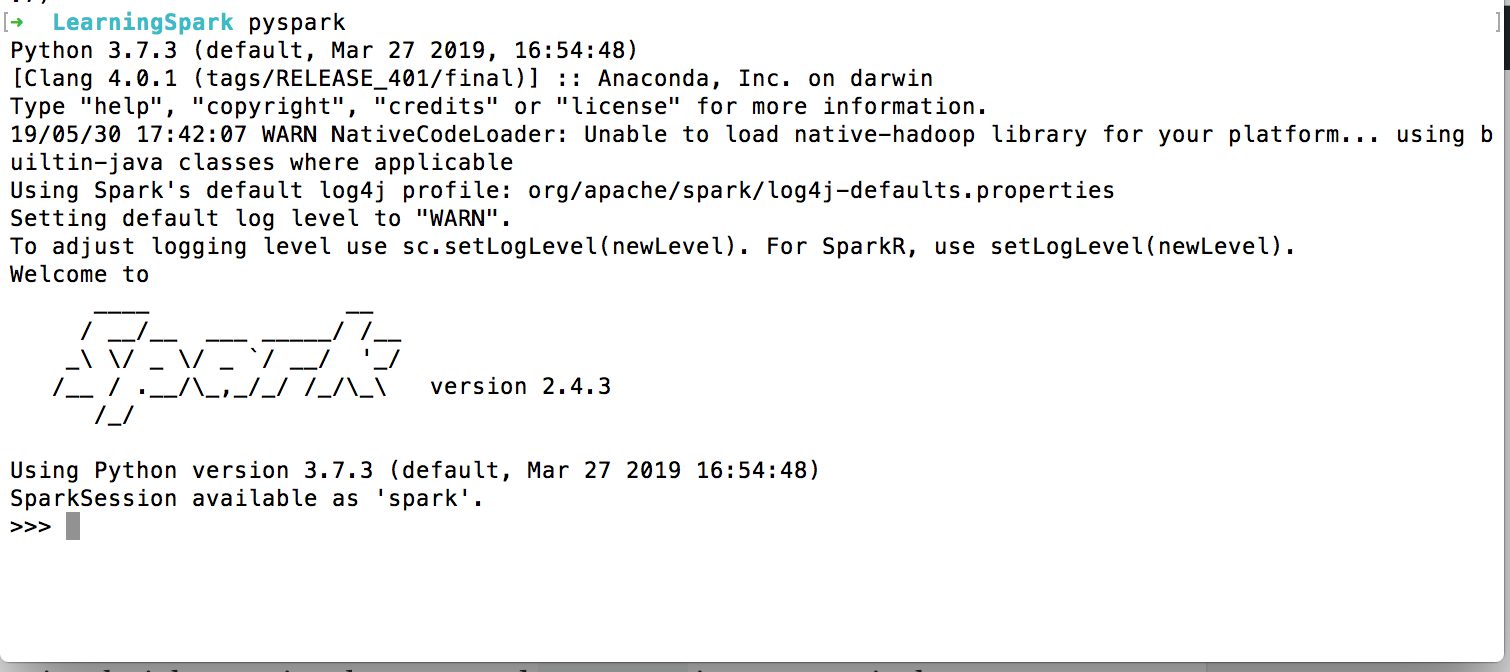
You find a typical Python shell but this is loaded with Spark libraries.
Let’s start writing our first program.
from pyspark.sql import SparkSession
from pyspark.sql import SQLContextif __name__ == '__main__':
scSpark = SparkSession \
.builder \
.appName("reading csv") \
.getOrCreate()
We have imported two libraries: SparkSession and SQLContext.
SparkSession is the entry point for programming Spark applications. It let you interact with DataSet and DataFrame APIs provided by Spark. We set the application name by calling appName. The getOrCreate() method either returns a new SparkSession of the app or returns the existing one.
To get in-depth knowledge, enroll for a live free demo on ETL Testing Certification
ETL is the process by which data is extracted from data sources (that are not optimized for analytics), and moved to a central host (which is). The exact steps in that process might differ from one ETL tool to the next, but the end result is the same.
At its most basic, the ETL process encompasses data extraction, transformation, and loading. While the abbreviation implies a neat, three-step process – extract, transform, load – this simple definition doesn’t capture:
Historically, the ETL process has looked like this:
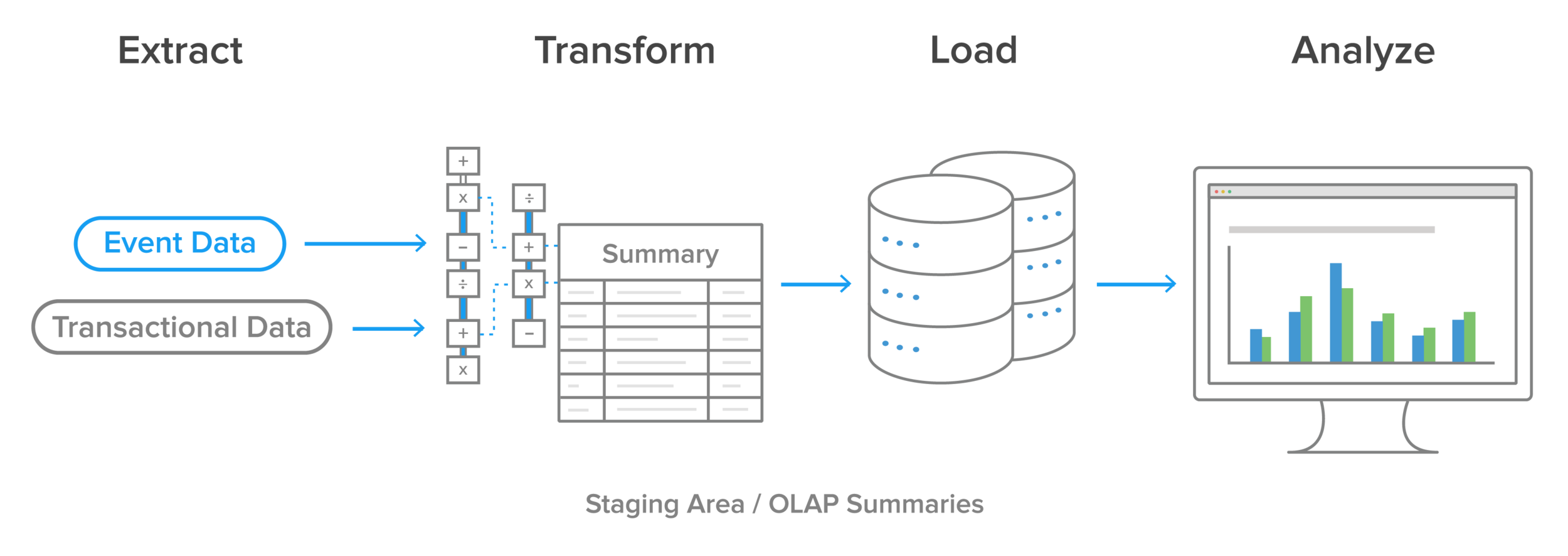
Data is extracted from online transaction processing (OLTP) databases, today more commonly known just as ‘transactional databases’, and other data sources. OLTP applications have high throughput, with large numbers of read and write requests. They do not lend themselves well to data analysis or business intelligence tasks. Data is then transformed in a staging area. These transformations cover both data cleansing and optimizing the data for analysis. The transformed data is then loaded into an online analytical processing (OLAP) database, today more commonly known as just an analytics database. For more info ETL Testing Training
Business intelligence (BI) teams then run queries on that data, which are eventually presented to end users, or to individuals responsible for making business decisions, or used as input for machine learning algorithms or other data science projects. One common problem encountered here is if the OLAP summaries can’t support the type of analysis the BI team wants to do, then the whole process needs to run again, this time with different transformations.
Modern technology has changed most organizations’ approach to ETL, for several reasons.
The biggest is the advent of powerful analytics warehouses like Amazon Redshift and Google BigQuery. These newer cloud-based analytics databases have the horsepower to perform transformations in place rather than requiring a special staging area.
Another is the rapid shift to cloud-based SaaS applications that now house significant amounts of business-critical data in their own databases, accessible through different technologies such as APIs and webhooks.
Also, data today is frequently analyzed in raw form rather than from preloaded OLAP summaries. This has led to the development of lightweight, flexible, and transparent ETL systems with processes that look something like this: More ETL Testing Certification
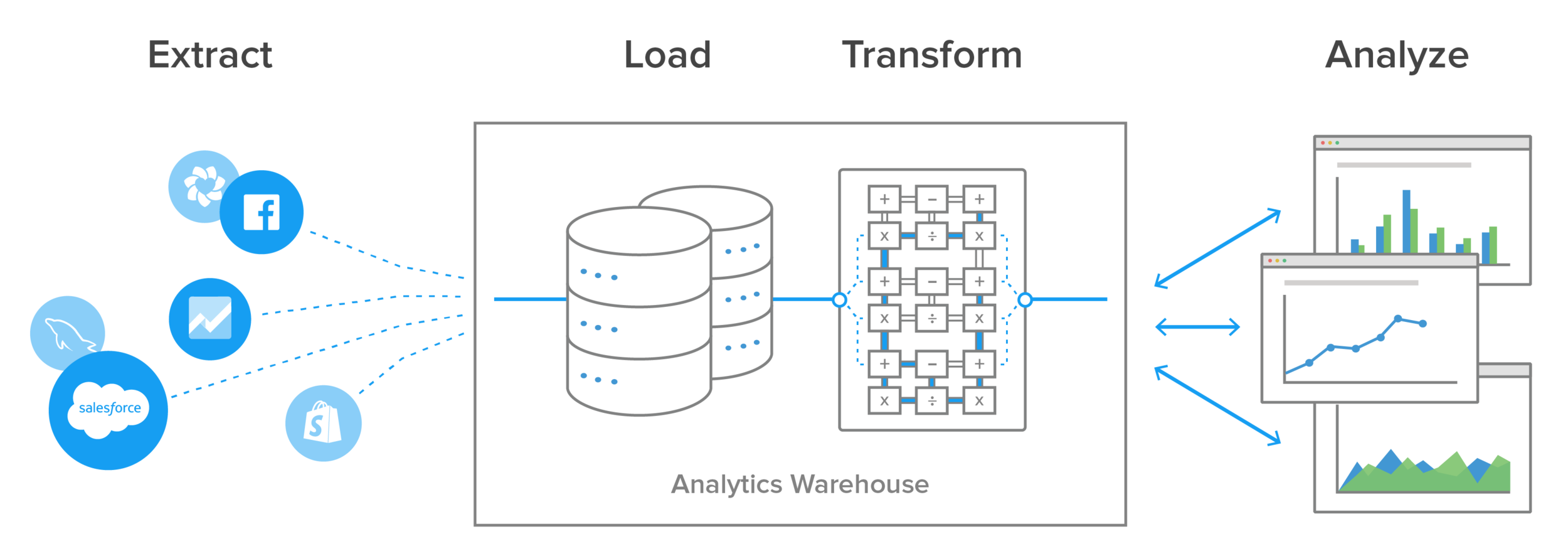
A comtemporary ETL process using a Data Warehouse
The biggest advantage to this setup is that transformations and data modeling happen in the analytics database, in SQL. This gives the BI team, data scientists, and analysts greater control over how they work with it, in a common language they all understand.
Regardless of the exact ETL process you choose, there are some critical components you’ll want to consider:
To get in-depth knowledge enroll for a live free demo on ETL Testing online training
As they face ever-changing business requirements, our customers need to adapt quickly and effectively. When we designed Workday’s original architecture, we considered agility a fundamental requirement.
We had to ensure the architecture was flexible enough to accommodate technology changes, the growth of our customer base, and regulatory changes, all without disrupting our users. We started with a small number of services. The abstraction layers we built into the original design gave us the freedom to refactor individual services and adopt new technologies.
These same abstractions helped us transition to the many loosely-coupled distributed services we have today. For more info Workday Online Course
At one point in Workday’s history, there were just four services: User Interface (UI), Integration, OMS, and Persistence. Although the Workday architecture today is much more complex, we still use the original diagram below to provide a high-level overview of our services.
At the heart of the architecture are the Object Management Services (OMS), a cluster of services that act as an in-memory database and host the business logic for all Workday applications. The OMS cluster is implemented in Java and runs as a servlet within Apache Tomcat. The OMS also provides the runtime for XpressO — Workday’s application programming language in which most of our business logic is implemented. Reporting and analytics capabilities in Workday are provided by the Analytics service which works closely with the OMS, giving it direct access to Workday’s business objects.
The Persistence Services include a SQL database for business objects and a NoSQL database for documents. The OMS loads all business objects into memory as it starts up. Once the OMS is up and running, it doesn’t rely on the SQL database for read operations. The OMS does, of course, update the database as business objects are modified. Using just a few tables, the OMS treats the SQL database as a key-value store rather than a relational database. Although the SQL database plays a limited role at runtime, it performs an essential role in the backup and recovery of data.
The UI Services support a wide variety of mobile and browser-based clients. Workday’s UI is rendered using HTML and a library of JavaScript widgets. The UI Services are implemented in Java and Spring. Get skills from Workday Online Training
The Integration Services provide a way to synchronize the data stored within Workday with the many different systems used by our customers. These services run integrations developed by our partners and customers in a secure, isolated, and supervised environment. Many pre-built connectors are provided alongside a variety of data transformation technologies and transports for building custom integrations. The most popular technologies for custom integrations are XSLT for data transformation and SFTP for data delivery.
The Deployment tools support new customers as they migrate from their legacy systems into Workday. These tools are also used when existing customers adopt additional Workday products.
Workday’s Operations teams monitor the health and performance of these services using a variety of tools. Realtime health information is collected by Prometheus and Sensu and displayed on Wavefront dashboards as time series graphs. Event logs are collected using a Kafka message bus and stored on the Hadoop Distributed File System, commonly referred to as HDFS.
As we’ve grown, Workday has scaled out its services to support larger customers, and to add new features. The original few services have evolved into multiple discrete services, each one focused on a specific task. You can get a deeper understanding of Workday’s architecture by viewing a diagram that includes these additional services. Click play on the video above to see the high-level architecture diagram gain detail as it transforms into a diagram that resembles the map of a city. (The videos in this post contain no audio.)
This more detailed architecture diagram shows multiple services grouped together into districts:
These services are connected by a variety of different pathways. A depiction of these connections resembles a city map rather than a traditional software architecture diagram. As with any other city, there are districts with distinct characteristics. We can trace the roots of each district back to the services in our original high-level architecture diagram.
There are a number of landmark services that long-time inhabitants of Workday are familiar with. Staying with the city metaphor, users approaching through Workday Way arrive at the UI services before having their requests handled by the Transaction Services. Programmatic access to the Transaction Service is provided by the API Gateway. Get more skills from Workday Integration Training
The familiar Business Data Store is clearly visible, alongside a relatively new landmark: the Big Data Store where customers can upload large volumes of data for analysis. The Big Data Store is based on HDFS. Workday’s Operations team monitors the health and performance of the city using the monitoring Console based on Wavefront.
Zooming in on the User Interface district allows us to see the many services that support Workday’s UI.
The original UI service that handles all user generated requests is still in place. Alongside it, the Presentation Services provide a way for customers and partners to extend Workday’s UI. Workday Learning was our first service to make extensive use of video content. These large media files are hosted on a content delivery network that provides efficient access for our users around the globe. Worksheets and Workday Prism Analytics also introduced new ways of interacting with the Workday UI. Clients using these features interact with those services directly. These UI services collaborate through the Shared Session service which is based on Redis. This provides a seamless experience as users move between services.
This architecture also illustrates the value of using metadata-driven development to build enterprise applications.
Application developers design and implement Workday’s applications using XpressO, which runs in the Transaction Service. The Transaction Service responds to requests by providing both data and metadata. The UI Services use the metadata to select the appropriate layout for the client device. JavaScript-based widgets are used to display certain types of data and provide a rich user experience. This separation of concerns isolates XpressO developers from UI considerations. It also means that our JavaScript and UI service developers can focus on building the front-end components. This approach has enabled Workday to radically change its UI over the years while delivering a consistent user experience across all our applications without having to rewrite application logic. Learn financials from Workday Financials Training
The Object Management Services started life as a single service which we now refer to as the Transaction Service. Over the years the OMS has expanded to become a collection of services that manage a customer’s data. A brief history lesson outlining why we introduced each service will help you to understand their purpose.
Originally, there was just the Transaction Service and a SQL database in which both business data and documents were stored. As the volume of documents increased, we introduced a dedicated Document Store based on NoSQL.
Larger customers brought many more users and the load on the Transaction Service increased. We introduced Reporting Services to handle read-only transactions as a way of spreading the load. These services also act as in-memory databases and load all data on startup. We introduced a Cache to support efficient access to the data for both the Transaction Service and Reporting Services. Further efficiencies were achieved by moving indexing and search functionality out of the Transaction Service and into the Cache. The Reporting Services were then enhanced to support additional tasks such as payroll calculations and tasks run on the job framework.
Search is an important aspect of user interaction with Workday. The global search box is the most prominent search feature and provides access to indexes across all customer data. Prompts also provide search capabilities to support data entry. Some prompts provide quick access across hundreds of thousands of values. Use cases such as recruiting present new challenges as a search may match a large number of candidates. In this scenario, sorting the results by relevance is just as important as finding the results.
A new search service based on Elasticsearch was introduced to scale out the service and address these new use cases. This new service replaces the Apache Lucene based search engine that was co-located with the Cache. A machine learning algorithm that we call the Query Intent Analyzer builds models based on an individual customer’s data to improve both the matching and ordering of results by relevance.
Scaling out the Object Management Services is an ongoing task as we take on more and larger customers. For example, more of the Transaction Service load is being distributed across other services. Update tasks are now supported by the Reporting Services, with the Transaction Service coordinating activity. We are currently building out a fabric based on Apache Ignite which will sit alongside the Cache. During 2018 we will move the index functionality from the Cache onto the Fabric. Eventually, the Cache will be replaced by equivalent functionality running on the Fabric.
Integrations are managed by Workday and deeply embedded into our architecture. Integrations access the Transaction Service and Reporting Services through the API Gateway.
Watch the video above to view the lifecycle of an integration. The schedule for an integration is managed by the Transaction Service. An integration may be launched based on a schedule, manually by a user, or as a side effect of an action performed by a user.
The Integration Supervisor, which is implemented in Scala and Akka, manages the grid of compute resources used to run integrations. It identifies a free resource and deploys the integration code to it. The integration extracts data through the API Gateway, either by invoking a report as a service or using our SOAP or REST APIs.
A typical integration will transform the data to a file in Comma Separated Values (CSV) or Extensible Markup Language (XML) and deliver it using Secure File Transfer Protocol (SFTP). Learn HCM module from Workday HCM Training
The Integration Supervisor will store a copy of the file and audit files in the Documents Store before freeing up the compute resources for the next integration.
There are three main persistence solutions used within Workday. Each solution provides features specific to the kind of data it stores and the way that data is processed.
A number of other persistence solutions are used for specific purposes across the Workday architecture. The diagram above highlights some of them:
All of these persistence solutions also conform to Workday’s policies and procedures relating to the backup, recovery, and encryption of tenant data at rest.
Workday Prism Analytics provides Workday’s analytics capabilities and manages users’ access to the Big Data Store
Click play to view a typical Analytics scenario. Users load data into the Big Data Store using the retrieval service. This data is enhanced with data from the transaction service. A regular flow of data from the Transaction Server keeps the Big Data Store up to date.
Users explore the contents of the Big Data Store through the Workday UI and can create lenses that encapsulate how they’d like this data presented to other users. Once a lens is created, it can be used as a report data source just like any other data within the Transaction Server. At run-time the lens is converted into a Spark SQL query which is run against the data stored on HDFS.
Workday provides sophisticated tools to support new customers’ deployments. During the deployment phase, a customer’s data is extracted from their legacy system and loaded into Workday. A small team of deployment partners works with the customer to select the appropriate Workday configuration and load the data.
Workday’s multi-tenant architecture enables a unique approach to deployment. All deployment activity is coordinated by the Customer Central application, which is hosted by the OMS. Deployment partners get access to a range of deployment tools through Customer Central.
Deployment starts with the creation of a foundation tenant. Working in conjunction with the customer, deployment partners select from a catalog of pre-packaged configurations based on which products they are deploying. Pre-packaged configurations are also available for a range of different regulatory environments.
The next step is to load the customer’s data into the Big Data Store. The data is provided in tabular form and consultants use CloudLoader to transform, cleanse and validate it before loading it into the customers’ tenant.
Customer Central supports an iterative approach to deployment. Multiple tenants can easily be created and discarded as the data loading process is refined and different configuration options are evaluated. The Object Transporter service provides a convenient way to migrate configuration information between tenants. These tenants provide the full range of Workday features. Customers typically use this time to evaluate business processes and reporting features. Customers may also run integrations in parallel with their existing systems in preparation for the switch over.
As the go-live date approaches, one tenant is selected as the production tenant to which the customers’ employees are granted access. Customers may continue to use Customer Central to manage deployment projects for additional Workday products or to support a phased roll-out of Workday.
The primary purpose of these tools is to optimize the deployment life cycle. Initially, the focus is on the consulting ecosystem. As these tools reach maturity, customers gain more access to these features and functionality. In time, these tools will allow customers to become more self-sufficient in activities such as adopting new products, or managing mergers and acquisitions.
To get in-depth knowledge, enroll for a live free demo on Workday Training
Learn the differences between an event-driven streaming platform like Apache Kafka and middleware like Message Queues (MQ), Extract-Transform-Load (ETL), and Enterprise Service Bus (ESB). Including best practices and anti-patterns, but also how these concepts and tools complement each other in an enterprise architecture.
This post shares my slide deck and video recording. I discuss the differences between Apache Kafka as Event Streaming Platform and integration middleware. Learn if they are friends, enemies, or frenemies.

Extract-Transform-Load (ETL) is still a widely-used pattern to move data between different systems via batch processing. Due to its challenges in today’s world where real-time is the new standard, an Enterprise Service Bus (ESB) is used in many enterprises as integration backbone between any kind of microservice, legacy application, or cloud service to move data via SOAP/REST Web Services or other technologies.
Stream Processing is often added as its own component in the enterprise architecture for correlation of different events to implement contextual rules and stateful analytics. Using all these components introduces challenges and complexities in development and operations. For more info ETL Testing Certification

This session discusses how teams in different industries solve these challenges by building a native event streaming platform from the ground up instead of using ETL and ESB tools in their architecture. This allows us to build and deploy independent, mission-critical streaming, real-time applications, and microservices.
The architecture leverages distributed processing and fault-tolerance with fast failover, no-downtime, rolling deployments, and the ability to reprocess events, so you can recalculate output when your code changes. Integration and Stream Processing are still key functionality but can be realized in real time natively instead of using additional ETL, ESB or Stream Processing tools. Learn more from ETL Testing Training
A concrete example architecture shows how to build a complete streaming platform leveraging the widely-adopted open-source framework Apache Kafka to build a mission-critical, scalable, highly performant streaming platform. Messaging, integration, and stream processing are all built on top of the same strong foundation of Kafka; deployed on-premise, in the cloud, or in hybrid environments. In addition, the open source Confluent projects, based on top of Apache Kafka, add additional features like a Schema Registry, additional clients for programming languages like Go or C, or many pre-built connectors for various technologies.

To get in-depth knowledge, enroll for a live free demo on ETL Testing Online Training
how we use Business Intelligence tools to visualise the mountains of data we accumulate in the course of our Performance Intelligence practice assignments. Even the practice name of “Performance Intelligence” reflects the vital role that such tools and techniques play in deriving insights from all of that data to allow us to get to the bottom of the really hard system performance problems.
Our data visualisation tool of choice is Tableau, because it connects to pretty much any type of data, offers a very wide range of visualisation types and can handle huge volumes of data remarkably quickly when used well.
But up until now we have always treated Tableau as a standalone tool sitting alongside whichever performance testing or metrics collections tools we are using on a performance assignment. For more info Tableau Training
That works fine – but it does mean that the analysis and visualisation doesn’t form an integral part of our workflow in these other tools.
There are lots of opportunities to streamline the workflow, allowing interactive exploration of test results data – drilling down from high-level summaries showing the impact to low-level detail giving strong clues about the cause of issues. If only we could carry context from the performance testing tool to the visualisation tool.
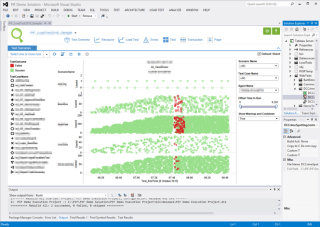
We have recently been working to address that, making use of an integration API which Tableau introduced with their last major release.
First cab off the rank for us was integrating the visualisations into the Microsoft Visual Studio development environment, since that provides one of the performance testing tools which we use extensively in our practice, and the Microsoft Visual Studio environment offers the extensibility points necessary to achieve tight integration.
But whilst the integration is conceptually straightforward – we just want the visualisations to form a seamless part of the experience of using the tool and to know the context (what is the latest test run, for example), actually making it work seamlessly and perform well required careful design and significant software development skills.
The Tableau API uses an asynchronous programming model – JavaScript Promises (so called because when you call an asynchronous method the response you get back is not the answer you are after but a “promise” to return it in due course).
Using this asynchronous model allows the client-side behaviour to remain responsive whilst potentially long-running requests involving millions of rows of data are handled on the Tableau server Training.
Putting a simplistic proof-of-concept together was within my powers, but actually achieving tight integration in a robust and well performing way definitely needed the professionals.
So I’m very glad that we had the services of our Business Application and Product Development business available to do the integration work.
We’re very pleased with the end result, and the folk at Tableau liked it enough to invite me to talk about it at their annual user conference in Seattle – which this year will have a staggering 5,000 attendees.
As part of my conference session I put together a simple demonstration to show how the interactions work. It is a simple standalone web page with an embedded Tableau visualisation object in it – showing how the user can interact with the Tableau visualisation both from controls on the hosting web page and from within the Tableau object itself.
To get in-depth knowledge, enroll for a live free demo on Tableau Online Training
Nowadays, most of the HR professionals are aware of the Human Capital Management technology. By selecting the correct HCM technology the human resource will be able to streamline the various HR processes that saves a lot of time and money of the organizations. With the latest business environment, regulation and technology, the employer not only have to pay compensation to the staff, however, they have to manage all the information of the employee and keep a record of each and everything related to them. In order to carry out this activity in an efficient way, the organization has to use a particular software that helps the employer to perform various activities. Presently, the cloud-based Human Capital Management technology is in very much demand by most of the organizations, that delivers every feature required by the company to manage their workforce. For more info Workday Training
There are various benefits of utilizing the cloud-based HCM technology in an organization. Some of the benefits are providing the security to the employee data, easy to track employee life cycle, it provides better employee commitment, getting the regular hardware and software advancements, etc. Considering all things, there are two most popular HCM solutions used by most of the organizations, they are SAP SuccessFactors and Workday HCM. They provide a wide variety of HR features to almost all sizes of the companies. The common features are recruiting, learning and development, compensation, payroll, talent management, etc. This post fundamentally demonstrates a comparison between the two HCM software on the basis of various parameters, which helps businesses to take the correct decision on the purchase of the software.
1. Outline of the Product:
The Workday was established by Dave Duffield and Aneel Bhusri in 2005. Workday HCM software is basically created for the medium to large companies with global employees, in order to manage their workforce in an effective way. It is an instinctive cloud-based software solution that is specifically designed to combine the HR and finance related data and features.
Whereas, SAP developed a new cloud-based HCM software, i.e. SAP SuccessFactors in 2011. It offers flexible core HR features including the three modules, i.e. Employee Central, Employee Central Payroll, and Employee central service center, to control the various HR processes. The SAP SuccessFactors provides the planned HR modules like learning and development, recruitment, payroll etc.
2. Features:
The various features provided by Workday HCM include, recruiting, talent management, learning, time and attendance management, workforce planning, payroll, benefits, and compensation. With Workday HCM it is possible to modify the business workforce requirements. It also involves workforce planning tools for the companies to analyze their staff like labor costs, etc. The users are able to grasp the dashboard that is modified by team, department or the entire company. By utilizing these dashboards, users can also have a look at the particular metrics, they can completely go through the data and can get an idea of what actions need to be taken.
On the other hand, the SAP SuccessFactors also includes a wide variety of core and planned HR features similar to Workday. Apart from the three modules, i.e. employee central, employee central payroll, and Employee central service center, it also offers different modules that creates a combined group. These modules include recruiting, onboarding, time and attendance management, workforce planning, etc. It also provides cross-site arrangements like enclosure and variety, health and wellbeing and total workforce management that help the companies to enhance their employee engagement. Learn more skills from Workday Integration Training
Both the software conveys relatively similar HR features, but these features may be differently delivered by each seller, like SAP SuccessFactors offers a devoted onboarding module, though Workday’s onboarding feature is integrated with performance management and succession-planning features with its talent management set, to carry out various functions.
3. Customer Support Services:
The clients who want to work with a devoted customer manager of the Workday, the Workday provides them a superior support facility and a customer success management program. The clients work with this dedicated manager on an enduring policy and obtain the benefits of using the Workday software continuously. The service involves the consistent review of the Workday practice, endorsement on further training and confirmation that the clients should receive the correct support for the troubleshooting concerns. For any questions or issues related to the usage of Workday, the client’s can interact directly with the support team. Not only this the users can also register a request to get the support through the online Workday Customer center. Once the request is registered, a case number, an approval mail, and the status updates will be received by the client. Then the generated request is directed to the responsible customer service representative who will look after the request and try to resolve the issues. Apart from these, the extra resources are also made available to the user’s by the Workday community, such as product documentation, get information on the latest features and can interconnect with the other clients.
Similarly, the SAP enterprise provision set involves a wide range of offerings for the customers. The customers can communicate and share their concepts on the issues with the general HR topics or software on the customer community. The customers can also glance through the article, videos and submitting support requirements using the support portal. Not only this, the users can also contact the support team through the live chat and can also get more knowledge about SuccessFactors through webinars. The SAP chosen Care option is also provided for the clients who want to work with the devoted support manager to solve any issues and queries. It offers best practices and mission-critical support for ever-increasing support problems. The support managers are also responsible to guide the customers for scaling up or down the solution and helping them in traversing through the latest releases of the product.
Well, both SAP SuccessFactors and Workday provides the same kind of customer service support and voluntary priority support and devoted support manager for the clients. The Workday does not have any option to contact the support through the live chat, but the SAP SuccessFactors provides this alternative to the clients.
4. Training and Implementation:
Workday’s deployment approach is performed by utilizing a partner network. It includes very generic five step deployment procedure. They are:
1. Review of the project plan
2. Review of the integration approach
3. Review of configuration prototype
4. Test review
5. And final configuration review.
Each process is carried out according to the client’s exclusive requirements. The workday completes the implementation of the new software within a year for almost 85% of its clients, nevertheless, implementation timelines may differ from company to company. The various training approaches are offered by Workday’s, such as on-demand training, classroom training, virtual classrooms training and self-service online training. It also contains an acceptance tool kit which comprises of job assistance, videos and marketing materials.
On the other hand, a wide collection of implementation services is offered by SAP SuccessFactors. These services include prepackaged plans for implementation to the companies that want a completely modified solution. SuccessFactors advisory Services team connect with the client to gather their exclusive requirements so that the best practices are planned for the SuccessFactors deployment. With the help of the SuccessFactors integration, delivery team, clients can integrate the SuccessFactors with either the SAP product or the current client applications. The SAP Education system offers the training program. It provides the certification programs and instructor-led specialized for various SuccessFactors modules. It also offers a subscription-based service called SAP learning Hub for its users, so that the training materials for its products are accessible to everyone anytime anywhere.
SuccessFactors and Workday have an overall implementation strategy, but the timelines and the phases are depend on the unique requirements of the client. The only difference between these two vendors are, the workday trusts on a partner network for its implementation while SAP depends on its in-house resources.
5. Limitations:
Though the Workday and SAP SuccessFactors are very good HCM software, they have some limitations too.
The Workday is not designed for smaller businesses, i.e. companies with less than a hundred staff, because it is an enterprise level software. Also, the Workday interface is not always instinctive to use, for example, it takes some time to finish certain procedures, like reports generation.
With the help of the report of some client’s it is observed that, the SAP SuccessFactors may be challenging to learn and not always easy to use. Also the customer service support may become slow sometimes, for example, to resolve a simple ticket, it may take one or two weeks.
There is a common limitation between the two software, the users have to learn the interface and they want a shorter click to execute the processes. It is important to ask the user’s references so that it is easy to find out the positive and negative experience of the users which they have come across while using the software.
To get in-depth knowledge, enroll for a live free demo on Workday Online training
It is a known fact that ETL testing is one of the crucial aspects of any Business Intelligence (BI) based application. In order to get the quality assurance and acceptance to go live in business, the BI application should be tested well beforehand.
The primary objective of ETL testing is to ensure that the Extract, Transform & Load functionality is working as per the business requirements and in sync with the performance standards.
Before we dig into ETL Testing with Informatica, it is essential to know what ETL and Informatica are.
Informatica PowerCenter is a powerful ETL tool from Informatica Corporation. It is a single, unified enterprise data integration platform for accessing, discovering, and integrating data from virtually any business system, in any
It is a single, unified enterprise data integration platform for accessing, discovering, and integrating data from virtually any business system, in any format and delivering that data throughout the enterprise at any speed. Through Informatica PowerCenter, we create workflows that perform end to end ETL operations.
Download and Install Informatica PowerCenter:
To install and configure Informatica PowerCenter 9.x use the below link that has step by step instructions: Get more from ETL Testing Certification
ETL testers often have pertinent questions about what to test in Informatica and how much test coverage is needed?
Let me take you through a tour on how to perform ETL testing specific to Informatica.
The main aspects which should be essentially covered in Informatica ETL testing are:
For better understanding and ease of the tester, ETL testing in Informatica can be divided into two main parts –
#1) High-level testing
#2) Detailed testing
Firstly, in the high-level testing:
In a nutshell, you can say that the high-level testing includes all the basic sanity checks.
Coming to the next part i.e. detailed testing in Informatica, you will be going in depth to validate if the logic implemented in Informatica is working as expected in terms of its results and performance.
To sum up, we can say that the detailed testing includes a rigorous end to end validation of Informatica workflow and the related flow of data.
Informatica is a popular and successful ETL tool because:
To get in-depth knowledge, enroll for a live free demo on ETL Testing Online Training

{kind=link}